Overview
With the increasing use of ML to power complex solutions have come intense scrutiny of whether the algorithms used in the solutions are safe for end-users. In that respect, and in line with Borealis’ mission towards the responsible development of ML algorithms, one of the key pillars of our RESPECT AI platform is Model governance. Rigorous model governance ensures model accountability, by having a determined set of checks and balances to namely address responsible AI considerations. Financial institutions typically have strong model governance, at the core of which is model validation. Validation ensures the trustworthiness of ML algorithms before they are launched into production by having sets of independent eyes vet models with established methodologies. In this blog, we detail the full validation pipeline as well as the contributions this project team made to each of the steps in this pipeline.
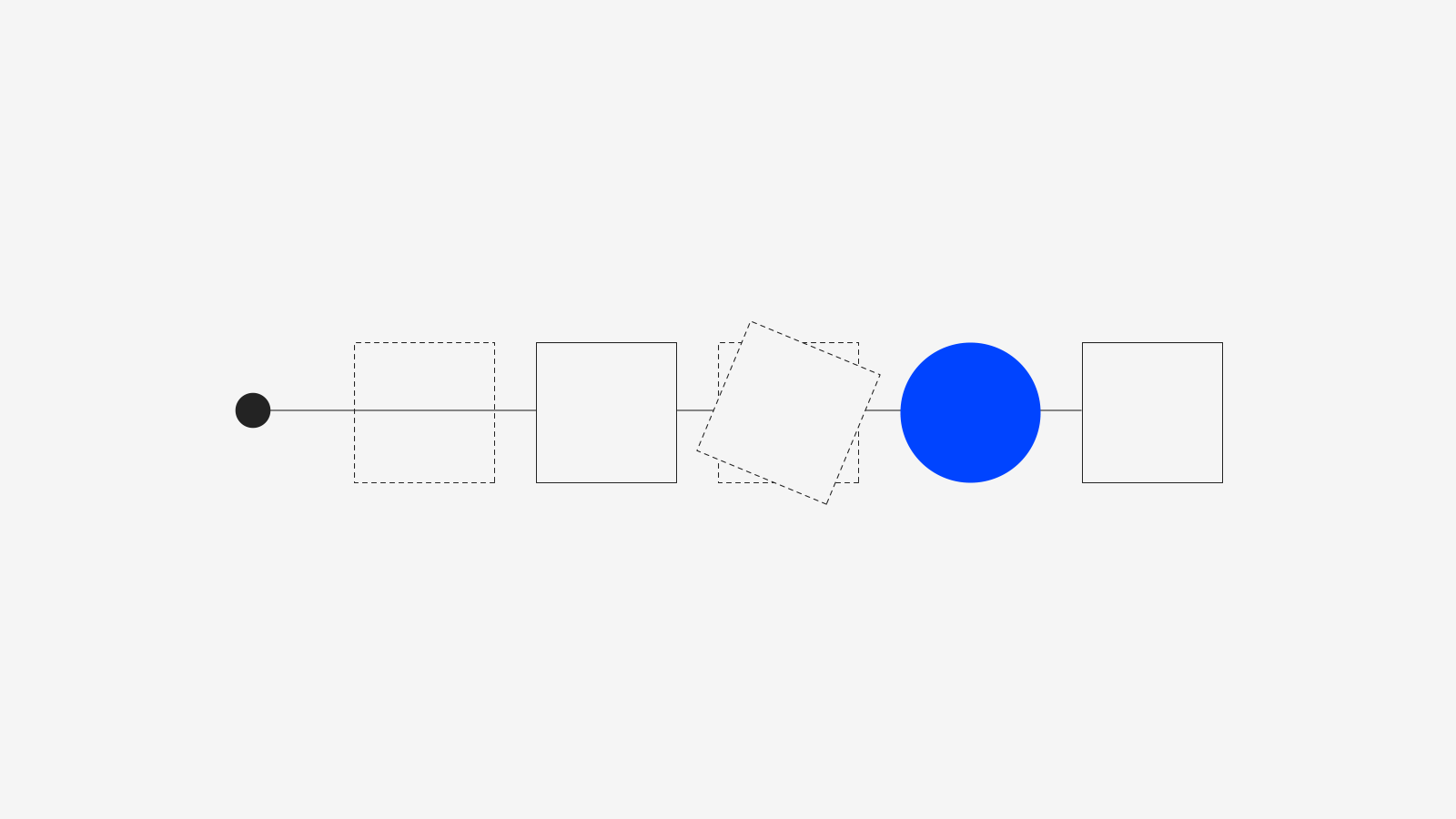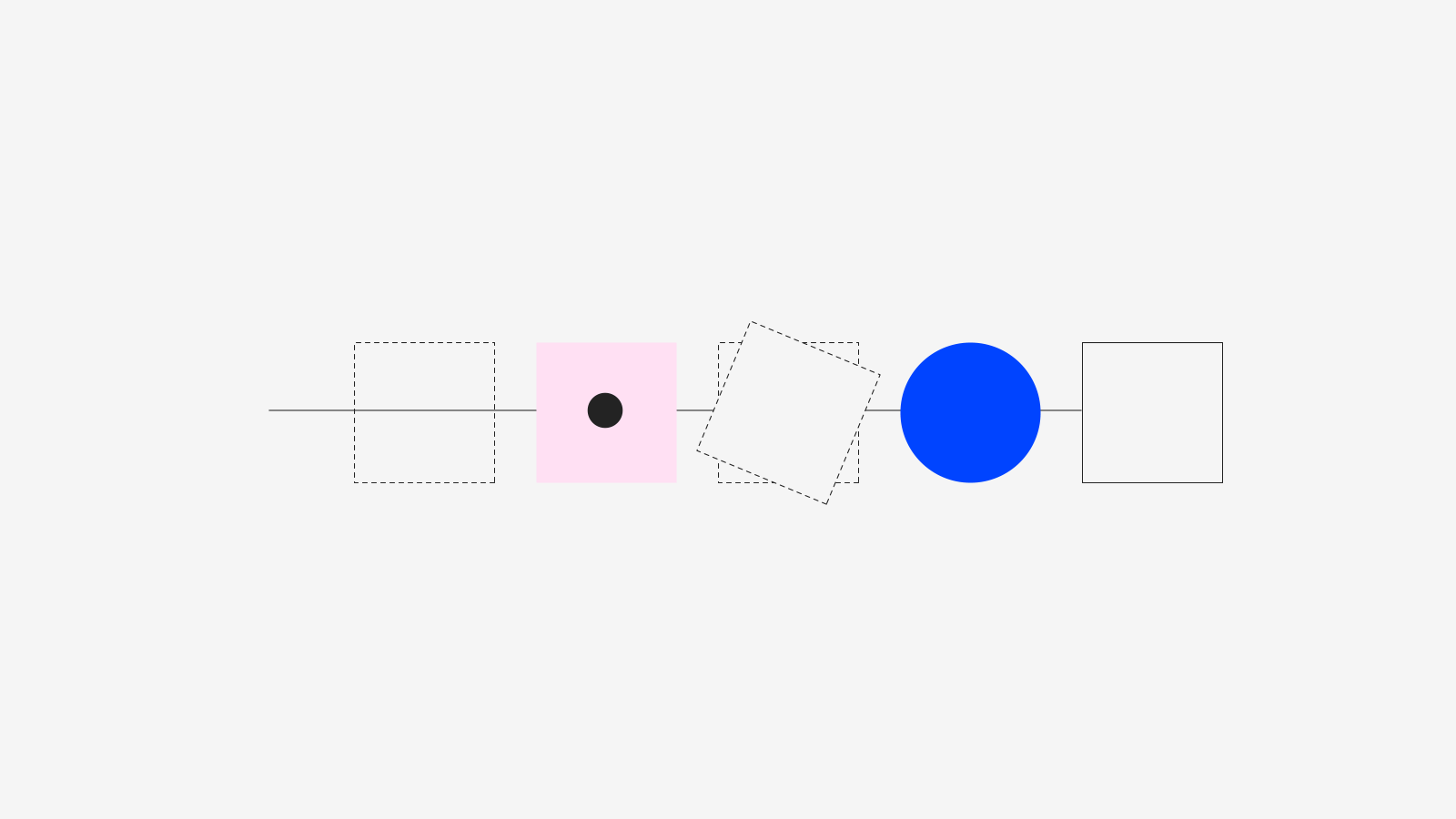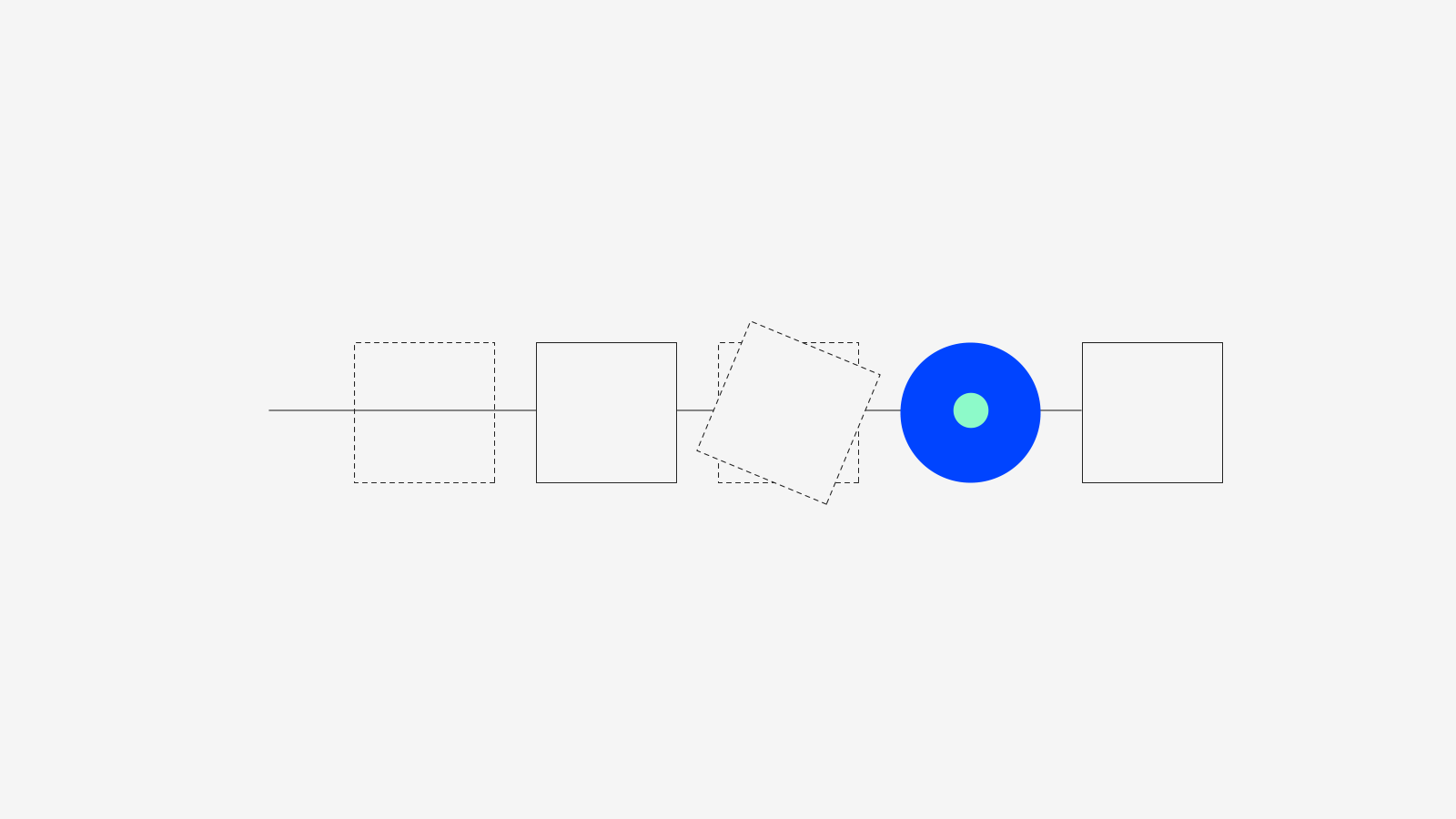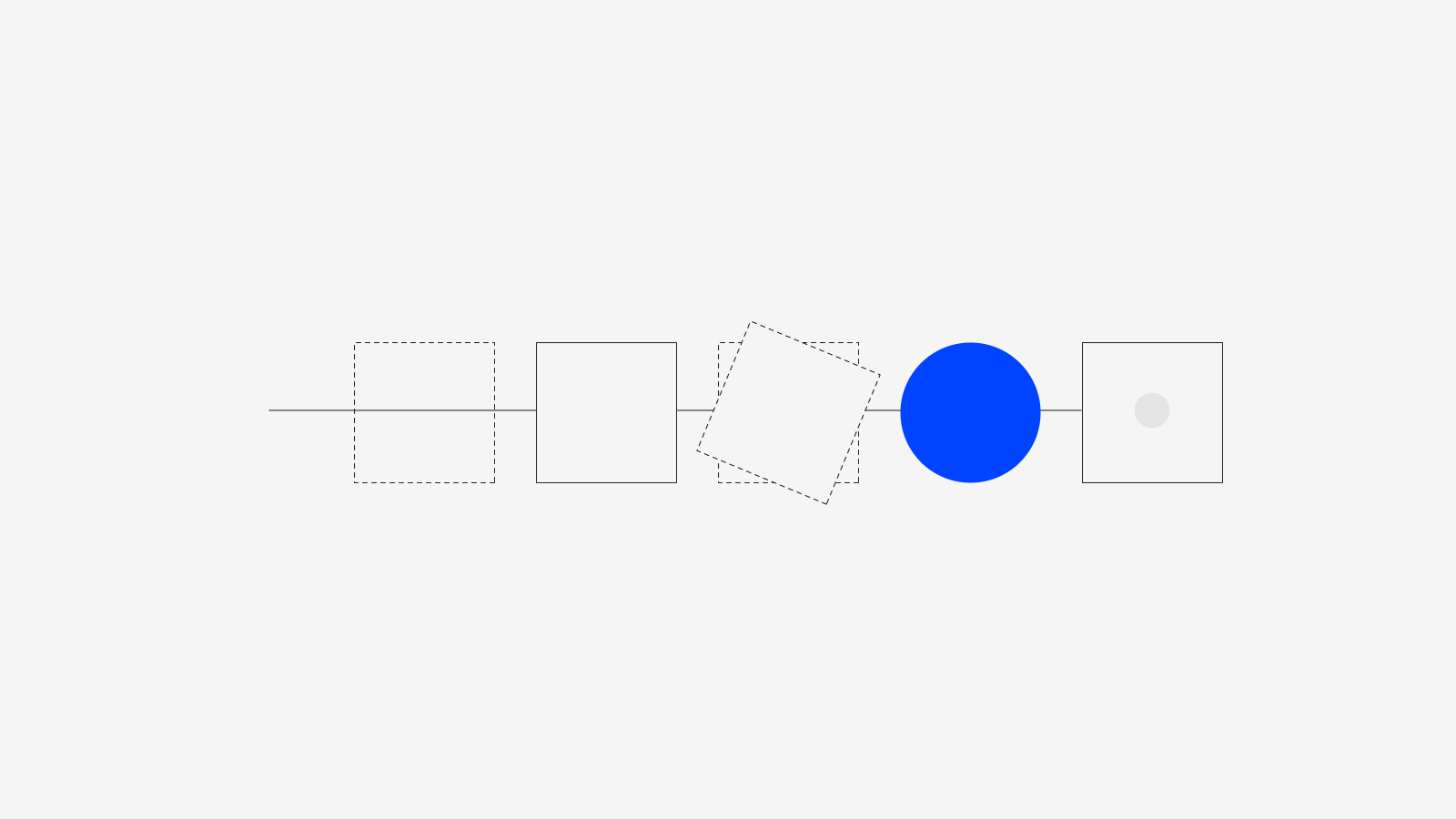
The validation pipeline, as shown in figure 1, details four main steps which we explore in the following sections.

Figure 1: Model validation pipeline.
Pre-checks
Before a model can even be assessed with regard to safety, we first need to make sure it is in a good state to do so. If this is not the case, the assessment mechanisms may flag issues incorrectly. For example, if an ML practitioner has failed to account for an imbalanced dataset when training their model, then an adversarial robustness test applied to the resulting model may not even function properly, to begin with. One can think of pre-checks as sanity checks to be done before even entering the validation pipeline. These pre-checks apply to both data and model. Examples of good pre-checks can be found in our pre-checks blog post Engineering Challenges in Automated Model Validation.
Assessment
Once pre-checks are complete, a submitted model can now be assessed with respect to various safety criteria. A model is assessed against a safety property, usually in the form of a mathematical equation. The equation below showcases one such example for adversarial robustness where we do not want a change in input x smaller than ε to change the output of the model f by more than δ.
\begin{align}
\text{property} = x^\prime-x < \epsilon \land f(x^\prime)-f(x) < \delta \label{eq:robustness} \tag{1}
\end{align}
The assessment itself may come in different forms. At one end of the spectrum is testing. In this scenario, the model is assessed against a property such as the one above, and if it fails the assessment, an example of this failure, known as a counter-example, is returned to the end user. At the other end of the spectrum from testing is certification. Unlike testing, certification methods are capable of returning a signature, ensuring that no counter examples exist. While certification is more thorough than testing, it is also more time-consuming. A full survey of certification methods can be found in our blog ‘Machine Learning Certification: Approaches and Challenges‘
Properties and Safety Considerations
When it comes to properties, there is as much debate in the field as to what they should cover in terms of safety considerations as there is about how they should be expressed. The example above given for adversarial robustness is a handcrafted mathematical translation of desired behaviour. However, much debate exists about this translation and handcrafting, particularly around whether there is bias in the way the expression is obtained in the first place. This is due to the difficulty that exists in taking a qualitative assessment of desired behaviour and attempting to form a representative mathematical expression for a software system to perform either testing or verification.
One particular area where this difficulty has been evident is in fairness. To date, there exist multiple handcrafted definitions of fairness. A few examples include demographic parity and equal opportunity, as detailed in this blog. However, to this day, there is still no consensus as to which should be used and even more so, some definitions conflict with each other. To circumvent the paradigm of handcrafted definitions and their applicability, one of Borealis’ biggest contributions in this space has been an attempt to this bridge this gap by coming up with a data-driven way to define fairness. More details can be found in our blog post ‘fAux: Testing Individual Fairness via Gradient Alignment‘.
Communication
Once a model has been assessed, it is important to relay the results to the end user in a way in which they can understand them. For example, one question that domain experts often ask us is: how likely is the failure likely to happen in practice? To answer this, we leaned into methods from out-of-distribution detection. Using these methods, we can take a distribution of counter-examples output from a test and compare that distribution against the training data distribution. A high overlap indicates that the failures are fairly realistic and likely to happen, while a low overlap indicates the opposite. You can find a full survey of OOD methods in our blog post ‘Out-of–distribution detection I: anomaly detection‘.
Correction
Assessing the model is half the battle. Fixing it is the other. One of the biggest issues in model remediation is the lack of an intuitive way to perform the fix itself. Suggested approaches include everything from retraining the model to changing the architecture. Complicating things further is that there is no consistency in which the fix is suggested. In this blog, we suggest a fix to this problem by providing a mechanism to fix models by up weighing and down weighing the training points. Even better, the procedure always remains the same. Whether the safety criteria are fairness, robustness, or something else, the fix is always provided to the end user in the same language of weights which should be applied to the data points to remedy the issue at hand.
Summary and Takeaways
Throughout this blog, we’ve shown you the steps involved in building a model validation pipeline. By doing so, our hope is to bring awareness to practitioners everywhere on what validators look at when assessing their models so that safety can be top of mind when developing these solutions in the first place. If you’d like to join such initiatives, be sure to check out our careers page.